
记录一次失败的数学建模
基于机器学习的颅内感染数据分析研究
**摘要:**本研究运用机器学习和数据分析技术,对颅内感染进行了深入研究。通过数据预处理、特征提取和模型训练等步骤,成功构建了预测颅内感染的机器学习模型。我们采用随机森林算法,并结合过采样技术解决类别不平衡问题,有效提高了模型的预测准确性。在模型验证阶段,各项性能指标均显示出模型具有良好的预测能力,可为医生提供辅助诊断。此外,数据分析还揭示了与颅内感染密切相关的因素,为临床治疗提供了新的线索。本研究不仅提升了颅内感染的诊断效率,也为未来医疗领域中机器学习和数据分析的广泛应用奠定了基础。
关键词: 颅内感染;数据分析;随机森林;朴素贝叶斯
目录
研究背景和意义
研究背景
在当今医疗科技迅猛发展的时代,颅内感染作为神经外科领域的一个重要议题,一直受到广泛的关注和研究。颅内感染不仅给患者带来极大的痛苦,还可能引发严重的并发症,甚至危及生命。因此,对于颅内感染的预防、诊断和治疗,一直是医学界研究的重点。近年来,随着机器学习和数据分析技术的不断进步,其在医疗领域的应用也日益广泛,为颅内感染的研究提供了新的思路和方法。
传统的颅内感染研究方法主要依赖于医生的临床经验和患者的临床表现,然而这种方法往往存在一定的主观性和局限性。首先,医生的临床经验虽然丰富,但受到个人知识和经验的影响,可能存在判断偏差。其次,患者的临床表现也可能受到多种因素的影响,如个体差异、病情严重程度等,导致诊断结果的不准确。因此,如何更准确地预测和诊断颅内感染,一直是医学界亟待解决的问题。
随着机器学习和数据分析技术的不断发展,其在医疗领域的应用也日益广泛。通过收集和分析大量的医疗数据,机器学习算法能够发现隐藏在数据中的规律和模式,为疾病的预测和诊断提供有力的支持。在颅内感染的研究中,机器学习和数据分析技术同样具有巨大的潜力。首先,通过收集和分析患者的医疗数据,如病史、症状、体征、影像学检查结果等,机器学习算法可以构建出预测颅内感染的模型。这些模型可以根据患者的个体特征和病情情况,预测患者发生颅内感染的风险和可能性,为医生提供更为准确的诊断依据。
其次,机器学习算法还可以对颅内感染的病因和发病机制进行深入的研究。通过对大量数据的分析,算法可以发现与颅内感染相关的因素和规律,为疾病的预防和治疗提供新的思路和方法。例如,通过分析手术室环境、医务人员操作等因素与颅内感染发生率之间的关系,可以制定出更为有效的预防策略。
此外,机器学习算法还可以应用于颅内感染的治疗方案优化。通过对患者的基因组学、影像学和临床数据等多个方面的信息进行分析和学习,算法可以为患者制定个性化的治疗方案,提高治疗效果和患者的生存率。综上所述,基于机器学习和数据分析的颅内感染研究具有重要的背景和意义。通过应用这些先进的技术和方法,我们可以更准确地预测和诊断颅内感染,为患者的健康保驾护航。
研究意义
颅内感染的影响因素多样,包括患者的年龄、性别、基础疾病(如免疫缺陷、糖尿病等)[1]、以前的医疗手术史、暴露于某些环境或地域因素,以及病原体的毒力和耐药性等。这些因素的复杂交互作用使得颅内感染的诊断和治疗成为一项挑战。分析这些影响因素可以帮助医生更好地理解疾病的发病机制,从而制定更有效的预防和治疗策略。
机器学习预测颅内感染的研究具有多方面的意义。通过训练包含大量患者数据的机器学习方法,可以构建出能够识别颅内感染风险的模型。这种模型能够综合考虑多种影响因素,并通过算法优化,提高预测的准确性。对于临床医生而言,这样的工具可以辅助他们在疾病早期阶段做出更准确的诊断,及时采取治疗措施,从而改善患者的预后。
利用机器学习进行颅内感染预测还能带来个性化医疗的优势。每个患者的情况都是独一无二的,机器学习模型可以根据个体的具体情况进行风险评估,为每位患者提供量身定做的监测和治疗方案。此外,机器学习模型还可以实时更新,随着新的数据和研究结果的出现而不断优化,确保预测工具始终基于最新的医学知识。在公共卫生层面,机器学习预测颅内感染的模型能够帮助卫生决策者了解哪些人群更易感染,以及在特定环境和条件下感染的风险。这对于制定针对性的预防措施、优化资源分配、减少医疗成本以及控制疾病传播都极为重要。
然而,要实现机器学习在预测颅内感染中的潜力,还需要克服一些挑战。数据的质量、多样性和可访问性是建立精确模型的关键。同时,必须保证模型的透明度和解释能力,以便医生和患者理解模型提供的预测和建议。
文献综述
颅内感染是一种涉及大脑和脊髓的严重疾病,可能由多种不同的病原体引起,包括细菌、病毒、真菌和寄生虫。这类感染可能导致一系列严重的神经系统并发症,甚至危及生命。因此,了解颅内感染的影响因素并采用机器学习技术预测感染的风险具有极其重要的临床和公共卫生意义。
在现有文献中,对颅内感染影响因素的分析已经揭示了多种与感染风险相关的因素。这些因素包括但不限于:患者的年龄、性别、基础疾病(如免疫缺陷、糖尿病等)[2]、以前的医疗手术史、暴露于某些环境或地域因素,以及病原体的毒力和耐药性等[3]。例如,一些研究表明,老年人和免疫系统受损的患者更容易发生细菌性脑膜炎[4]。同时,医院获得性感染,特别是在进行神经外科手术后,也是颅内感染的一个重要风险因素[5]。
近年来,机器学习技术在医学诊断和预测中的应用逐渐增多。在颅内感染的预测方面,研究者已经开始探索利用机器学习模型来预测感染的风险[6]。这些模型通常基于大量的患者数据,包括临床特征、实验室检查结果、影像学资料等,以训练算法识别潜在的感染风险[7, 8]。例如,一项研究使用逻辑回归和随机森林算法分析了细菌性脑膜炎的风险因素,并建立了预测模型。该模型展示了较高的敏感性和特异性,表明机器学习可以有效地用于颅内感染的预测[9]。机器学习预测颅内感染的研究不仅具有临床意义,也对公共卫生决策有重要影响。通过准确预测颅内感染的风险,可以帮助医生及时采取预防措施,减少感染发生率,同时优化医疗资源的分配[10]。此外,机器学习模型还可以帮助研究者更好地理解颅内感染的发病机制,为新的治疗方法的开发提供线索。
然而,文献也指出了机器学习在颅内感染预测中的一些挑战。数据的质量、多样性和可访问性是建立精确模型的关键[11]。同时,必须保证模型的透明度和解释能力,以便医生和患者理解模型提供的预测和建议[12]。此外,模型的泛化能力也是一个重要的考虑因素,需要通过独立数据集的验证来确保模型的稳定性和可靠性[13]。
综上所述,颅内感染影响因素的分析和机器学习预测研究是一个新兴且充满潜力的领域。尽管存在挑战,但现有文献表明,机器学习技术有望为颅内感染的预测和管理提供有力的工具,从而改善患者的治疗结果和生活质量。随着技术的不断进步和数据的积累,机器学习在颅内感染预测和治疗中的应用将变得越来越广泛,对提高人口健康水平和医疗质量产生深远影响。
数据介绍和预处理
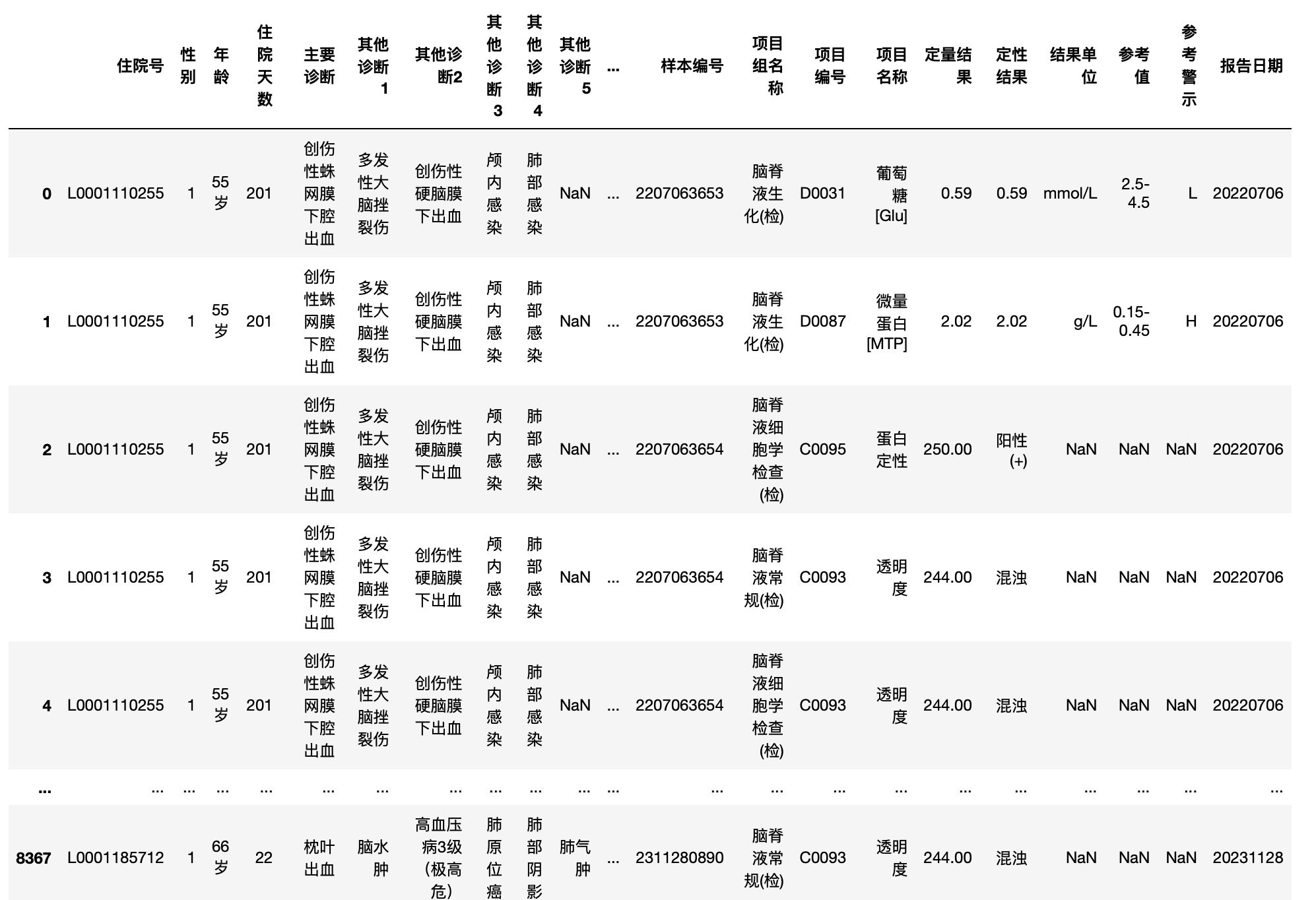
本次所采用的数据如上图所示,包含8372个样本和35个变量,其中大部分是文本型变量,例如诊断结果,手术名称和麻醉名称等。从上图中可以看到,样本中存在不少的缺失值,在数据分析中,当存在缺失值时,如果处理不当,可能会导致模型产生偏差,因为大多数算法会简单地忽略含有缺失值的记录,这可能会造成重要的信息丢失,特别是当缺失值不是随机出现的时候。此外,缺失数据还可能引入噪声,影响模型的准确性和解释性。在医学研究中,病人的某些检查指标缺失可能与其疾病状态密切相关,若忽略了这一点,就可能得出错误的结论。因此,首先对缺失值进行统计,结果如下:

图中柱状图不完整的部分即缺失值存在的地方,可以看到缺失值主要存在诊断和手术麻醉这几个变量中,结合实际情况这主要是因为大部分病人没有涉及10个诊断或者多项手术,因此这里先对缺失进行填充为无,后续再进行合并处理。
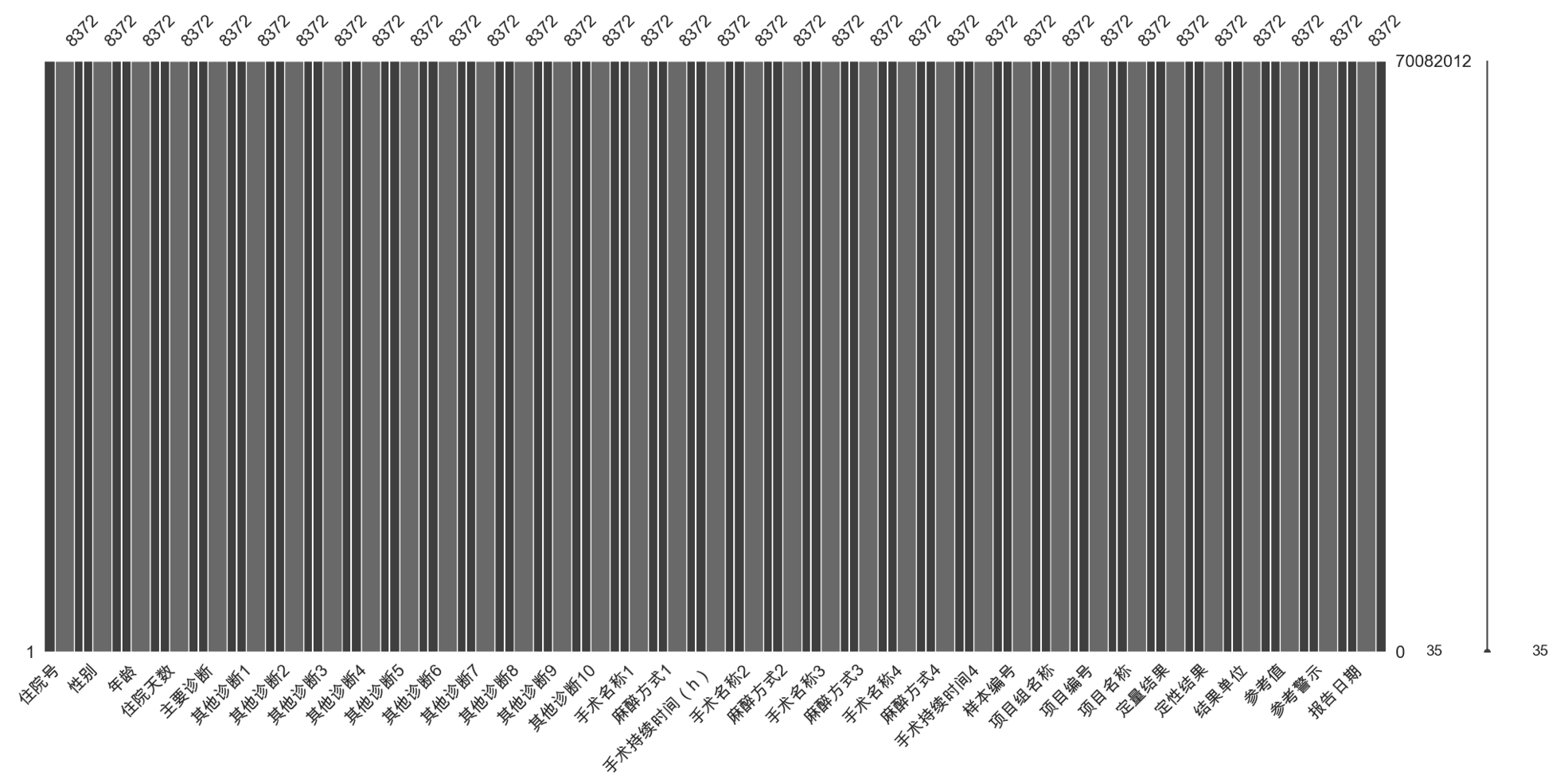
缺失值处理后对其再次进行可视化分析,可以看到所有变量下的样本都达到了8372个,不存在缺失值,可以进行后续分析。
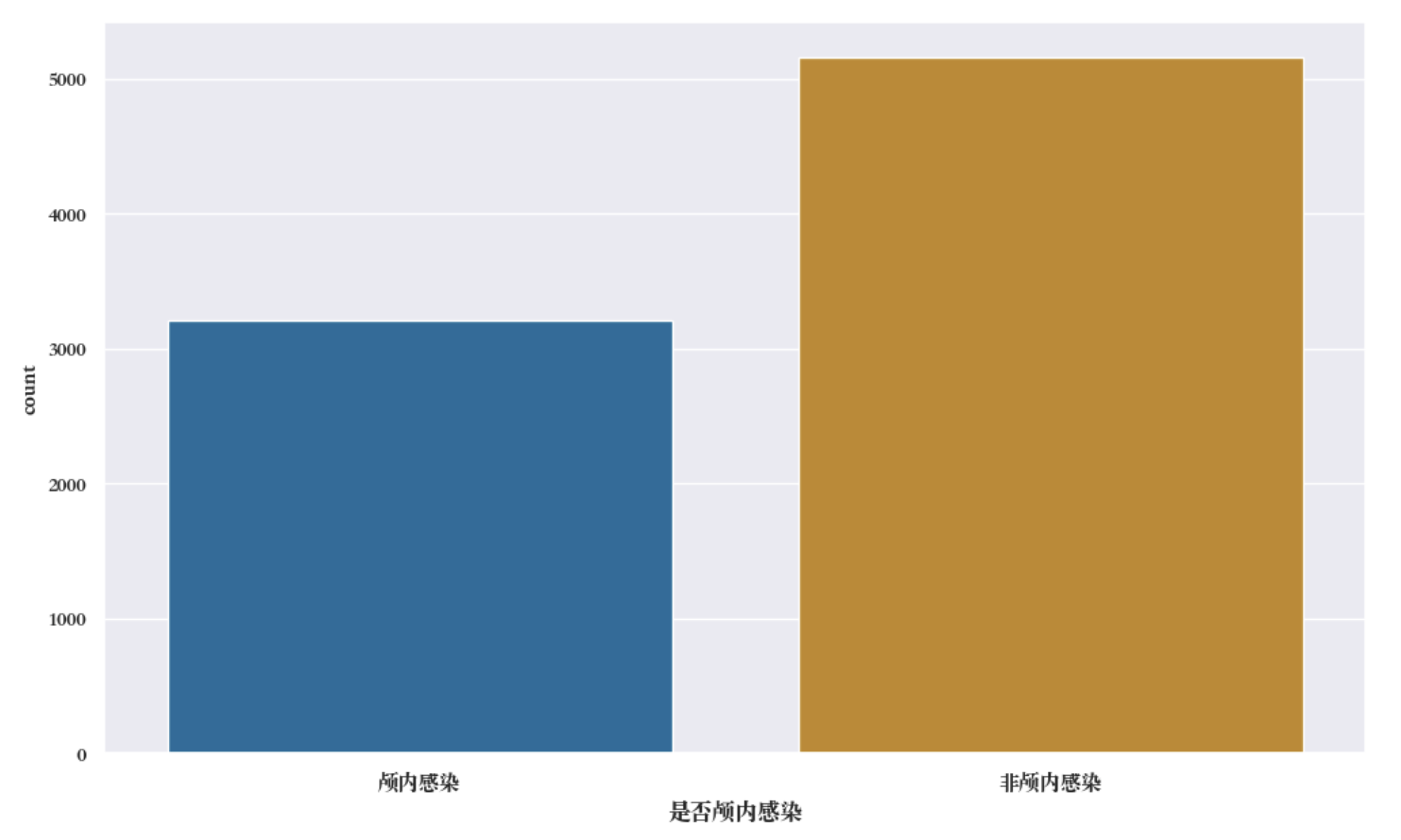
由于是否颅内感染随机分布在十个诊断中的其中一个,因此这里先对齐进行合并,在综合判断该样本中是否存在有关颅内感染的描述,如果有的话标记为颅内感染,没有的话标记为非颅内感染,最后进行统计分析,结果如上图所示,可以看到样本中非颅内感染的数量更多,达到了5000个样本,颅内感染有关的达到了3000个。
颅内感染影响因素分析
颅内感染相关病症分析
首先,本文认为颅内感染的出现可以与其他症状有关联性,即有些症状会增加颅内感染的可能性,或者颅内感染会很大程度导致这种症状的发现,其次有些症状可能会一致颅内感染的发生,基于这个假设,再结合数据中都是文本类型的数据,这里采用词云图进行分析。
首先是非颅内感染数据对应的词云图:

词云图是一种视觉化技术,用于以直观的方式显示文本数据中单词的频率。在词云中,单词的大小通常与它在文本中的出现频率成正比,即出现次数越多的单词,在图中的显示就越大。这种表示方式可以快速地传达出文本的关键信息,便于读者一眼看出重要内容。词云图的制作过程一般包括以下几个步骤:首先,需要对文本进行预处理,包括标准化(如转换为小写)、去除停用词(如“和”、“是”等常见但信息量小的词)、词干提取等。接下来,统计每个单词的出现频率。然后,根据频率和其他可选因素生成视觉化的词云图。
在非颅内感染的样本中,高频症状分别是出血、高血压、肺部、脑水肿和蛛网膜等词汇,接着对颅内感染的样本进行分析,结果如下:

在颅内感染的样本中,脑积水、蛛网膜、出血同样是高频词,但是高血压肺部、脑水肿等词的频率降低,此外,创伤性、血症脑室等症状增加,说明这些和颅内感染的关联性更强。
麻醉模式与颅内感染关联性分析
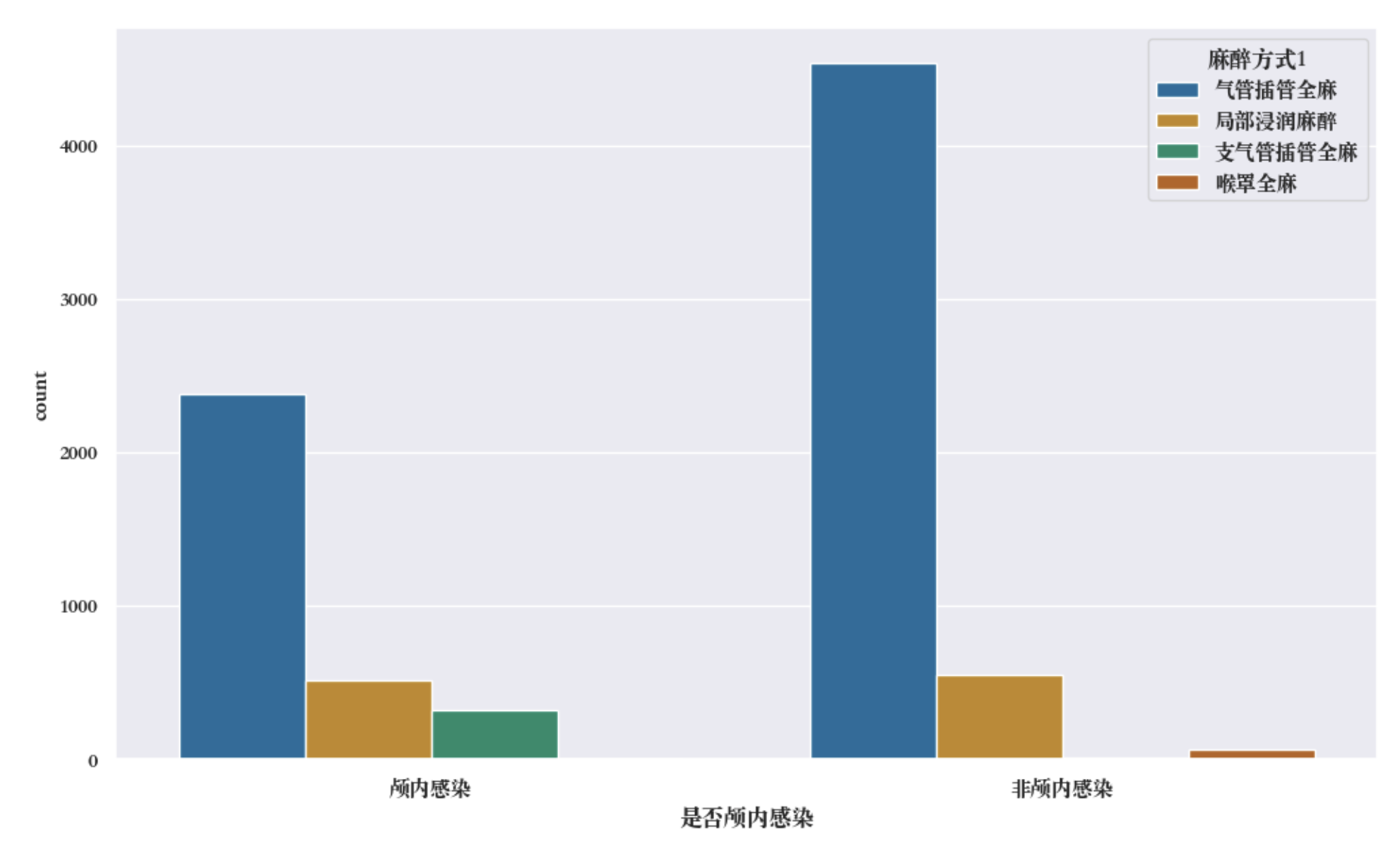
对颅内感染和非颅内感染对应的麻醉模型分别进行类别与数量统计,在一张图中用条形图进行可视化展示,首先,二者在气管插管全麻和局部浸润麻醉方面没有明显差异,但是在支气管插管全麻方面,颅内感染的情况明显高于非颅内感染。此外,喉罩全麻对应的结果其恰相反,颅内感染中几乎没有喉罩全麻的样本。
颅内感染与年龄关系分析
这里使用直方图对年龄的分布情况进行分析,直方图通过一系列高度不等的纵向条纹或线段来表示数据分布的情况,直方图能够显示各组频数或数量分布的情况,易于展示各组之间的差别。
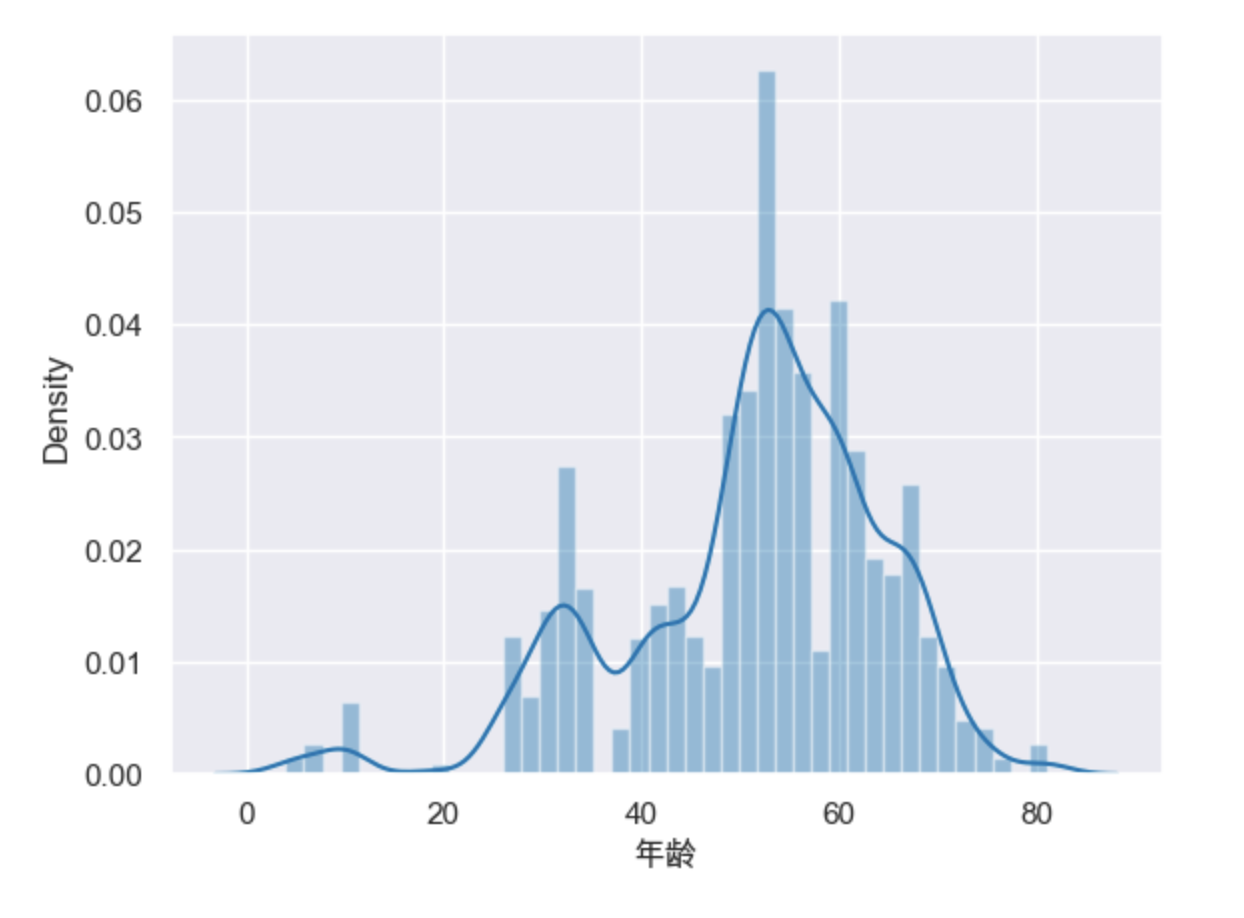
非颅内感染结果:
颅内感染结果:
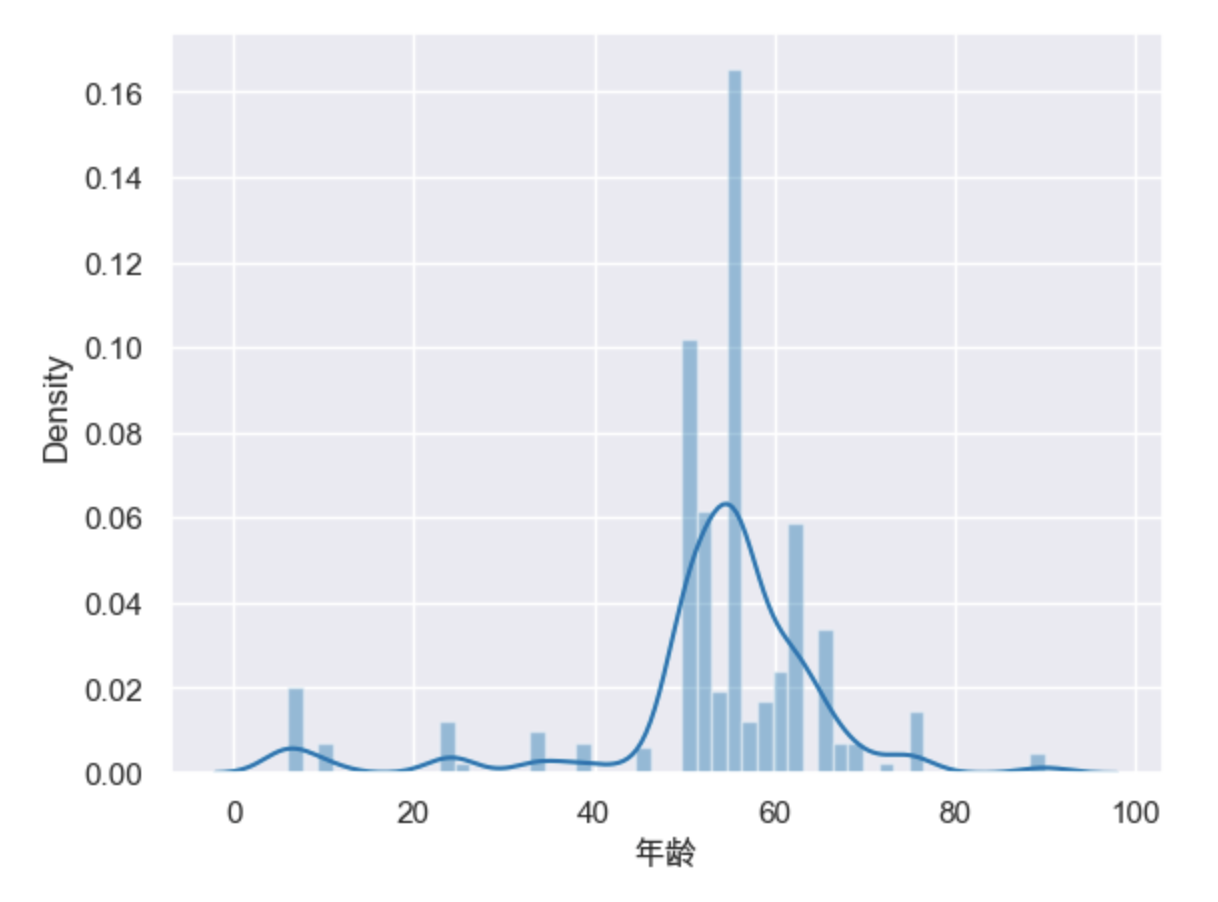
从可视化的结果来看,非颅内感染的群体年龄分布更广,在20-80这个区间内都有较多的分布,而非颅内感染主要集中在50-70这个区间段,从核密度曲线的走势变化来看,两种样本的情况基本相同,不存在显著差异。
颅内感染和性别关系分析
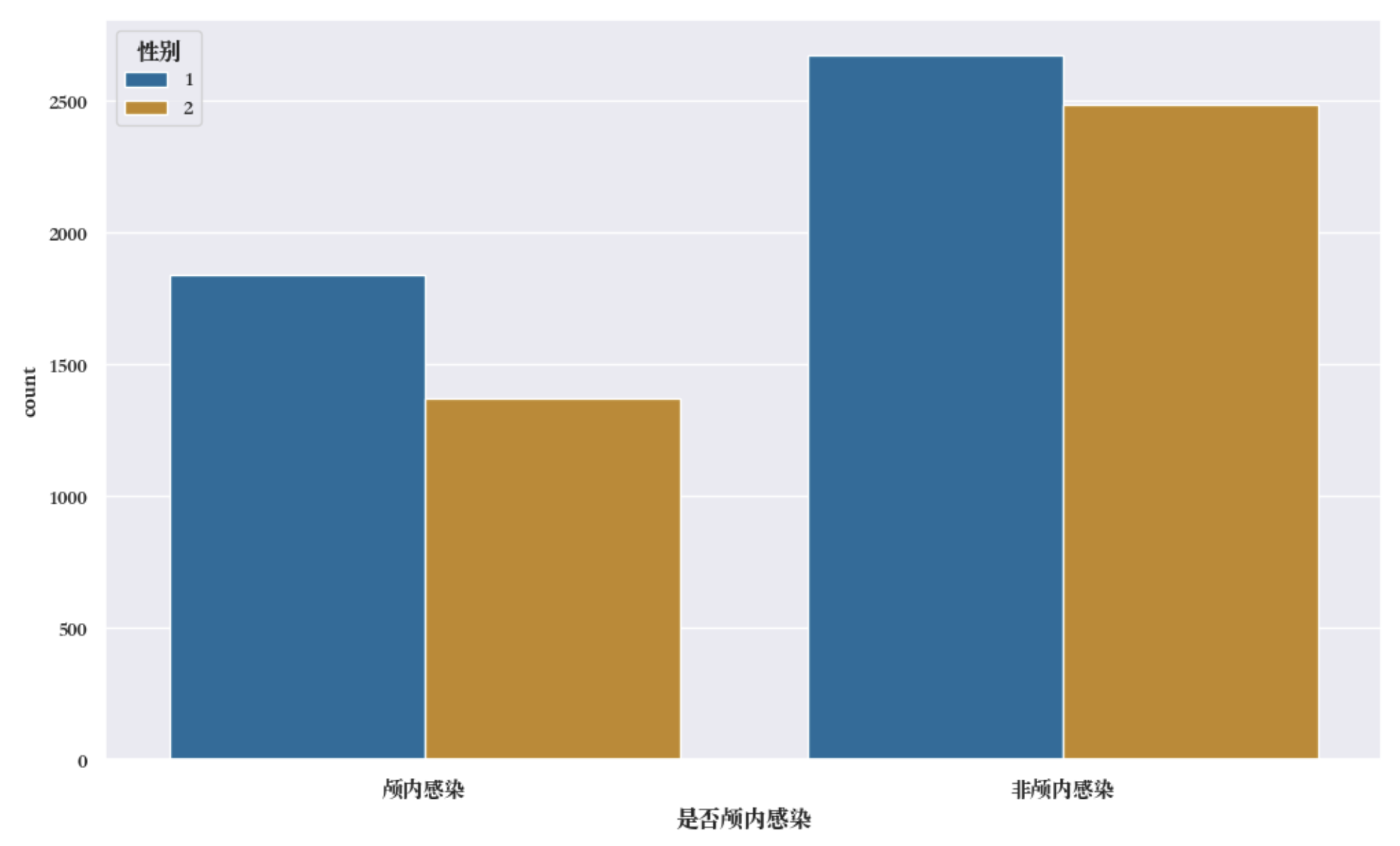
颅内感染样本中,女性群体的占比略微高于非颅内感染的群体,但是由于样本的数量不够大,因此会有比较多的随机误差影响,这里认为是否颅内感染和性别之间不存在显著差异。
颅内感染与手术类型相关性分析

在每一个手术类型下,都有不同程度的颅内感染情况的发生,但是有四种类型的手术,发生颅内感染的概率尤其大 ,分别是’脑内血肿清除术’、颅内血肿清除术’、‘脑室钻孔引流术’和’内镜下三叉神经微血管减压术’,这类手术直接与颅内有关。
颅内感染与住院天数关联性分析
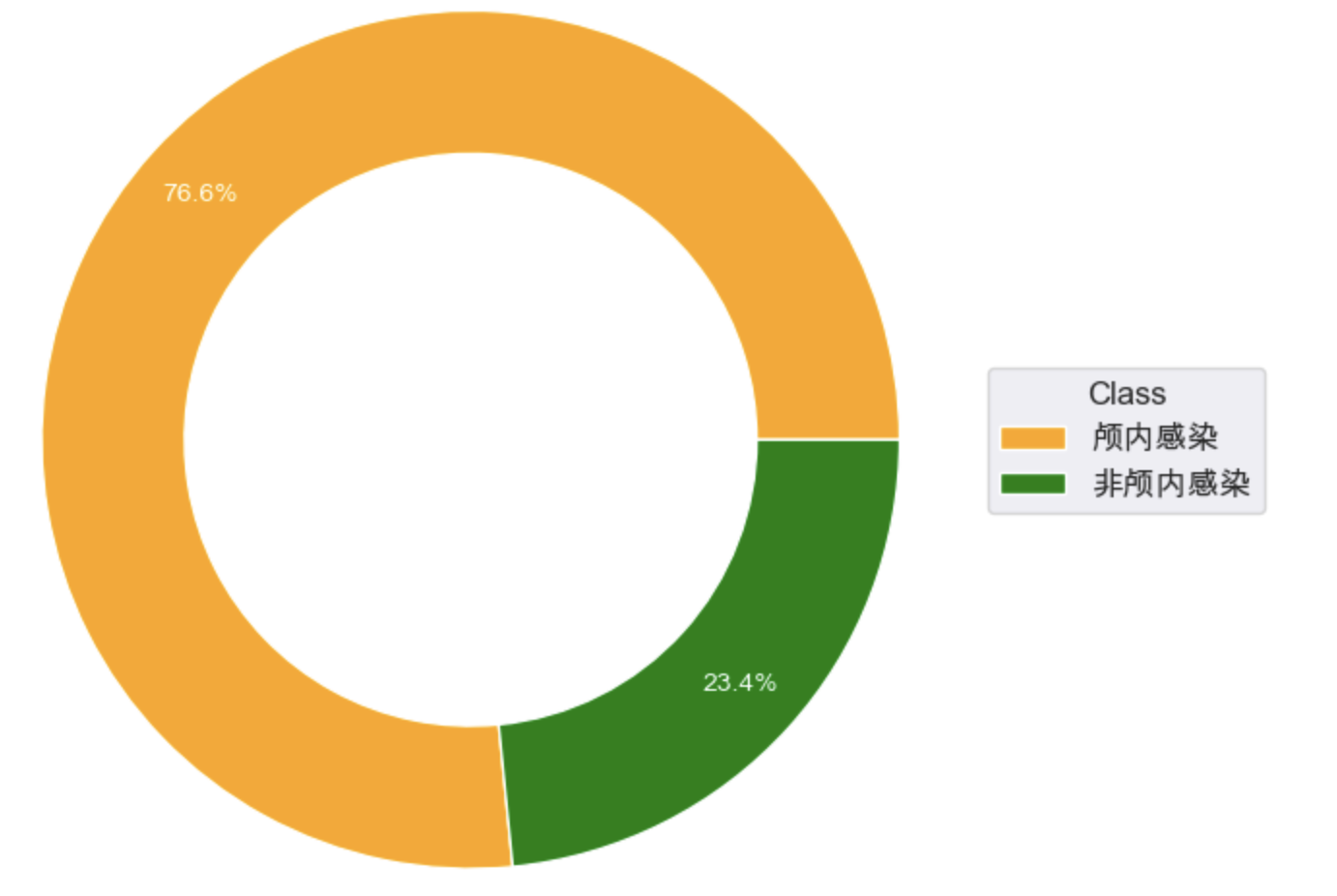
使用groupby函数对是否颅内感染进行分类统计,然后计算住院天数的均值,最后使用环形饼图进行展示,从结果来看,颅内感染的住院天数约为98天,非颅内感染的住院天数约为30天,占比只有百分之二十三点四,二者存在显著差异。
颅内感染风险模型建立
特征重要性分析
随机森林是一种集成学习方法,它通过建立多棵决策树并让它们进行投票来决定最终的分类或回归结果。而随机森林的特征重要性评估,是这一算法中一个极为关键的部分,它不仅揭示了模型在做出预测时各个特征的影响程度,还为我们优化模型、理解数据提供了有力的支持。
在随机森林中,特征重要性通常通过两种方式来计算:一是基于基尼不纯度的减少量,二是基于袋外数据)的错误率变化。当使用基尼不纯度时,随机森林会衡量在每个特征节点分裂前后数据的不纯度变化,变化越大,则表明该特征对于减少数据不纯度、提高模型准确性贡献越大,因此该特征的重要性就越高。而在基于袋外数据的特征重要性评估中,随机森林利用未被用于训练某棵树的数据(即袋外数据)来评估该树对于该部分数据的预测性能,随后通过随机打乱某个特征的值来观察预测性能的变化。如果打乱某个特征后预测性能显著下降,则表明该特征对于模型预测至关重要。
进行特征重要性分析可以帮助我们识别数据中的关键特征,这些特征对于模型的预测性能有着至关重要的影响。通过了解这些关键特征,我们可以更加深入地理解数据的本质和模型的工作原理。其次,特征重要性分析有助于我们进行特征选择和降维。在实际应用中,数据的特征维度往往非常高,这可能导致模型训练困难、过拟合等问题。通过评估特征的重要性,我们可以选择性地保留重要特征,去除冗余或无关紧要的特征,从而简化模型,提高模型的泛化能力。此外,特征重要性分析还有助于我们进行特征工程。通过了解不同特征对模型的影响程度,我们可以有针对性地对数据进行预处理、变换或组合,以生成更具代表性的新特征,进一步提高模型的性能。
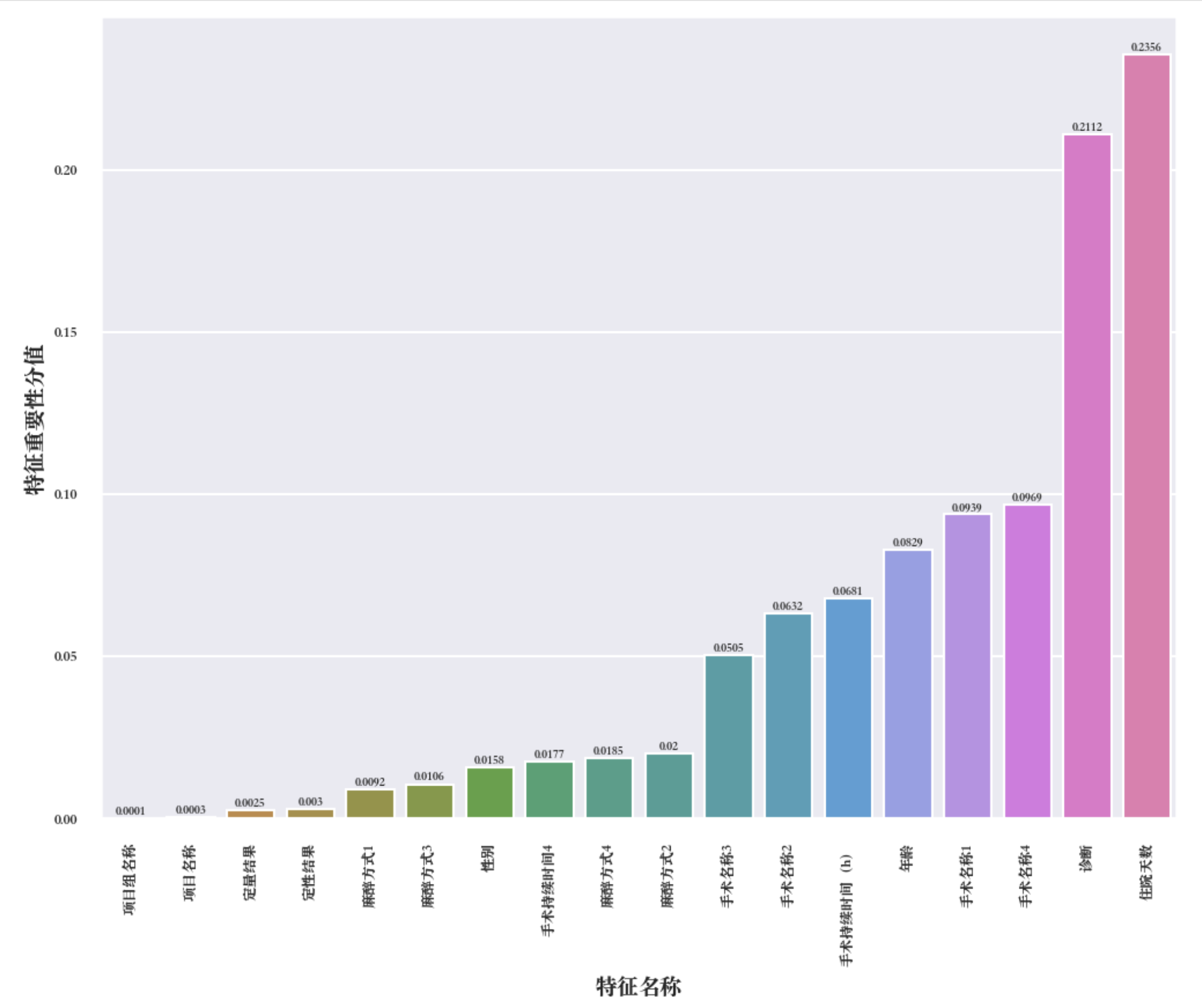
这里随机森林重要性分析的结果如上图所示,和前面探索性分析的结果一致,住院天数、诊断、手术类型等都对模型预测有了比较重要的贡献程度,而项目、定量结果、定型结果等对结果基本没有贡献,但是重要性大于0,而且这里特征数量不是特别多,因此对其进行保留。
基于朴素贝叶斯构建风险模型
朴素贝叶斯模型是一种基于贝叶斯定理与特征条件独立假设的分类方法。其核心思想在于,对于给定的待分类项,通过计算此项出现的条件下各个类别出现的概率,哪个概率最大,就认为此待分类项属于哪个类别。这里的“朴素”一词来源于其对于特征之间关系的简化假设,即假设特征之间相互独立,互不影响。
在朴素贝叶斯模型中,待分类项通常由一个特征向量表示,这个特征向量包含了多个特征,每个特征都是待分类项的一个属性。例如,在文本分类中,待分类项可能是一篇文章,而特征则可能是文章中的单词。模型首先需要根据训练数据集学习出各个特征在各类别中出现的概率,即先验概率。当需要对新的待分类项进行分类时,朴素贝叶斯模型会先计算该待分类项在各个类别下出现的概率,这个概率的计算基于贝叶斯定理和特征条件独立假设。具体来说,模型会先计算待分类项中每个特征在各个类别下出现的概率,然后将这些概率相乘(由于假设特征之间相互独立),得到待分类项在各个类别下出现的联合概率。最后,模型会选择联合概率最大的类别作为待分类项的预测类别。
朴素贝叶斯模型的构建流程如下:首先通过data.drop([‘是否颅内感染’], axis=1)移除了数据集中的因变量(即是否颅内感染这一列),保留了所有的自变量(特征),然后将因变量赋值给y。为了处理数据集中可能存在的类别不平衡问题(即颅内感染和非颅内感染样本数量不等),代码使用了SMOTE过采样技术,从少数类(颅内感染)中生成合成样本,使得两类样本数量相近。在数据预处理完成后,代码使用train_test_split函数将数据集划分为训练集和验证集,其中验证集占数据总量的30%。然后,定义了一个基于高斯分布的朴素贝叶斯分类器GaussianNB,并用训练集数据对其进行训练。训练完成后,代码使用验证集数据对模型进行了预测,并计算了接收者操作特征曲线(ROC曲线)下的面积(AUC值),这是评估二分类模型性能的一个重要指标。AUC值越接近1,说明模型的性能越好。
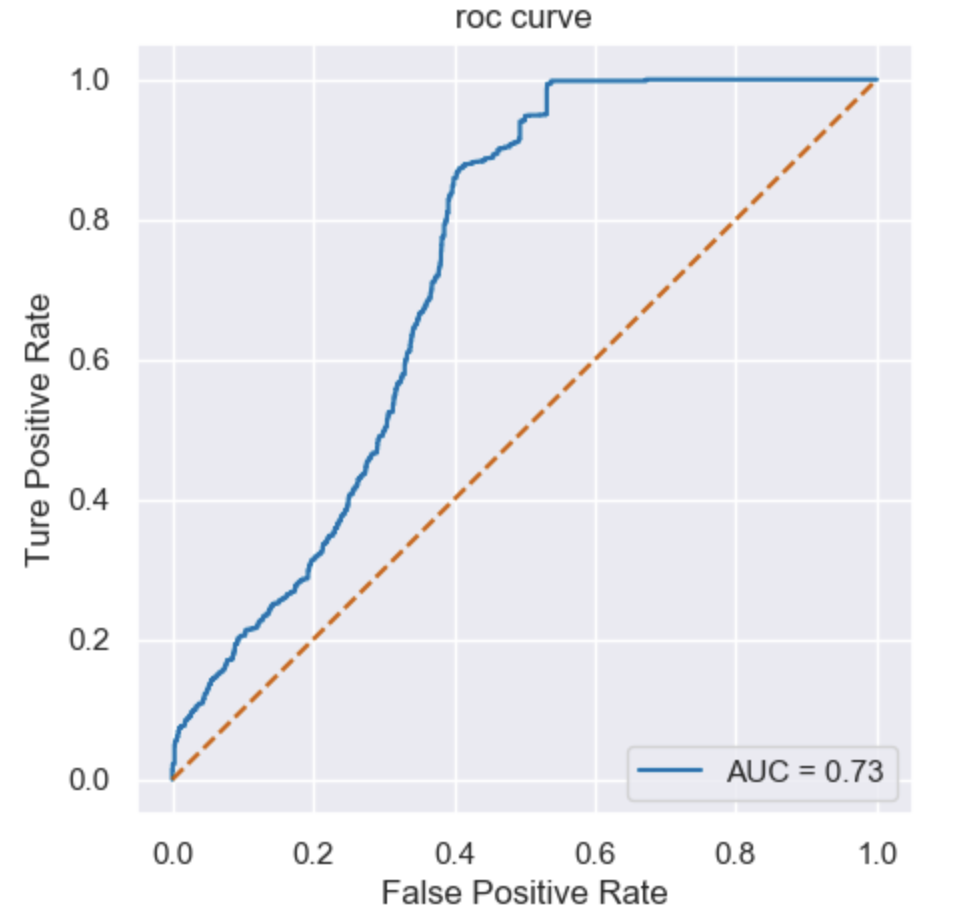
从roc曲线来看,朴素贝叶斯模型在一定程度上对是否颅内感染有预测能力,但是效果比较一般,在0.6以下的这个区域内,很少进行有效预测。
此外,还计算了模型的准确率、精确率、召回率和F1值,这些指标从不同角度评估了模型的性能。准确率衡量了模型预测正确的比例;精确率衡量了模型预测为正样本的实例中真正为正样本的比例;召回率衡量了所有真正为正样本的实例中被模型预测出来的比例;F1值是精确率和召回率的调和平均数,用于综合评估模型的性能。朴素贝叶斯的结果为:准确率0.7314396384764364,精确率0.6812182741116751,召回率0.8680465717981889,f值0.7633674630261661。为了进一步探索模型的性能,这里使用混淆矩阵进行分析:
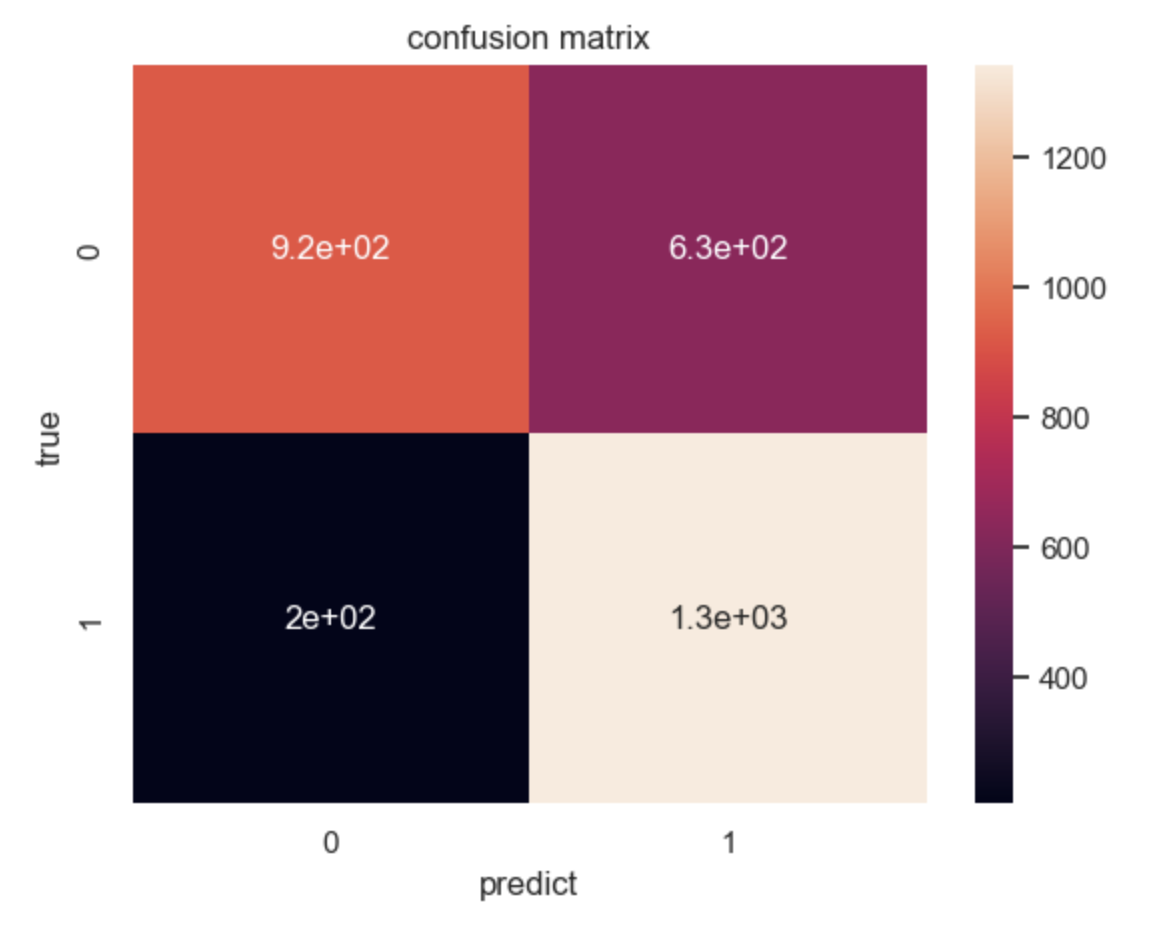
从图中来看,在朴素贝叶斯模型中,0标签预测正确有920个,预测错误有630个,1标签预测正确有1300个,预测错误有200个。说明该模型对1标签的预测能力更强,即预测非颅内感染的能力更好,不过这也跟数据样本不平衡有关。
基于随机森林构建风险模型
随机森林是一种强大的集成学习方法,它通过构建多个决策树并集成它们的预测结果来改进分类和回归任务的性能。随机森林模型的核心思想是利用“集思广益”的策略,通过随机选择特征和样本子集来训练多棵决策树,然后将这些决策树的预测结果进行投票或平均,以得出最终的预测结果。
在随机森林的构建过程中,每个决策树都是基于原始数据的一个随机子集进行训练的,这有助于减少过拟合现象,因为每个决策树都不会完全依赖于整个数据集。此外,每个决策树在分裂节点时,也会随机选择一部分特征作为候选分裂特征,而不是使用所有特征,这进一步增加了模型的多样性,提高了模型的泛化能力。
随机森林模型的主要优点包括高准确性:由于集成了多棵决策树的预测结果,随机森林通常能够获得比单一决策树更高的预测准确性。抗过拟合:通过随机选择特征和样本子集进行训练,随机森林模型能够有效地减少过拟合现象。特征重要性评估:随机森林模型能够计算每个特征对模型预测结果的重要性,这对于特征选择和解释模型预测结果非常有帮助。易于实现和调参:随机森林模型实现简单,参数较少,易于理解和调参。
这里随机森林模型的预测过程和贝叶斯基本相同,不再赘述,直接进行结果分析。
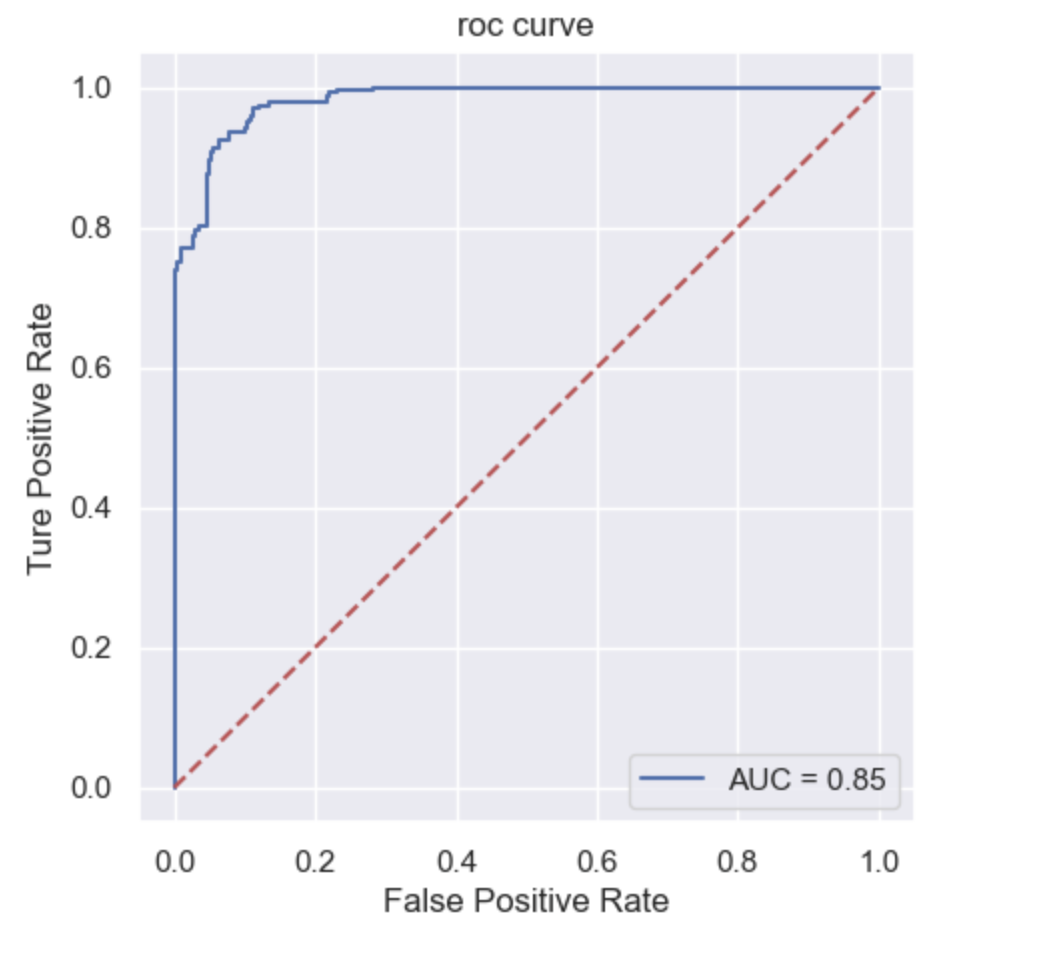
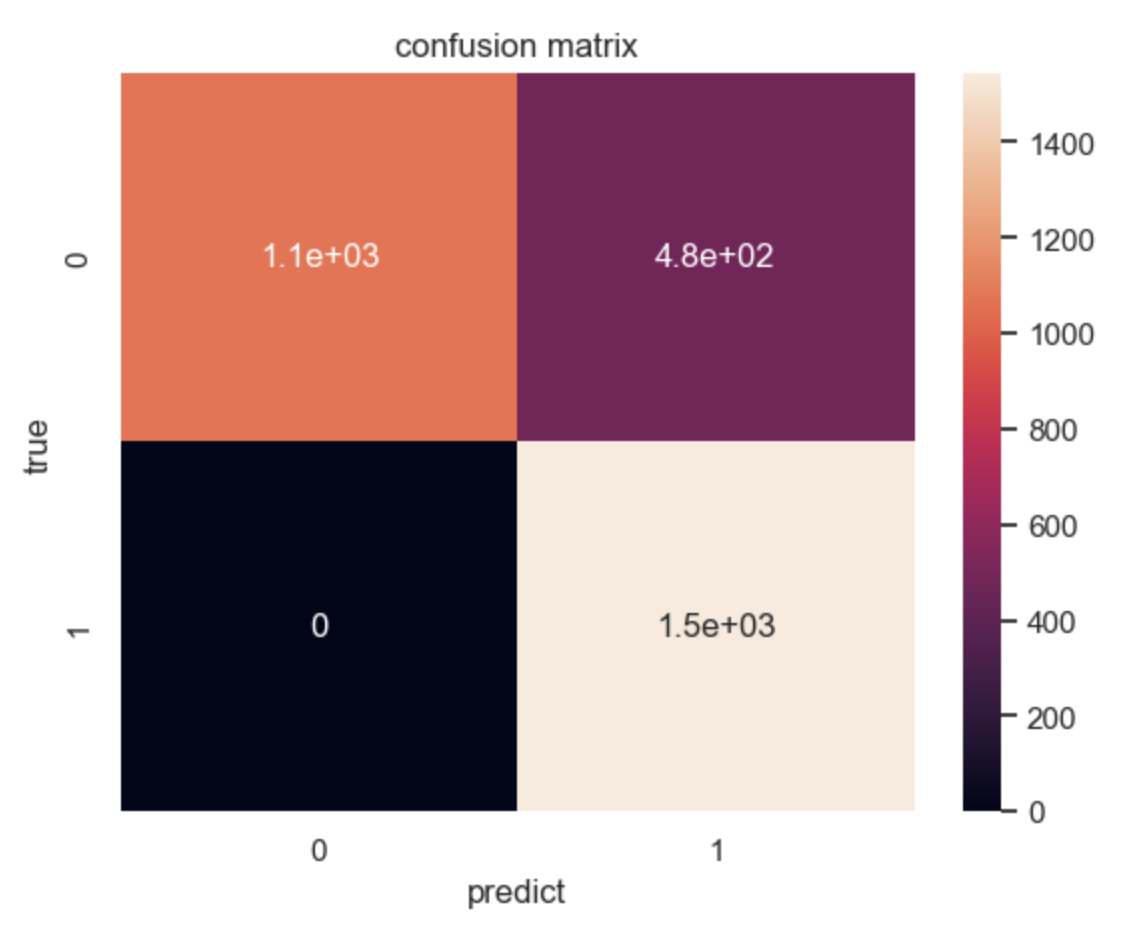
在随机森林模型中,auc值0.8456829896907216,准确率0.8453841187863137,精确率0.7634567901234568,召回率1.0,f值0.8658639036684402。再从roc曲线来看,整体走势更加平滑,能够有效对是否颅内感染进行预测,此外,0标签预测正确有1100个,预测错误有480个,1标签预测正确有1500个,预测错误有0个。虽然一样说明该模型对1标签的预测能力更强,即预测非颅内感染的能力更好,但是整体都实现了提升。
最后选择表现更加优秀的随机森林模型进行风险概率值的预测输出,结果如下:
总结
在医疗领域,颅内感染一直是一个严峻的挑战,它不仅对患者的生命安全构成威胁,同时也给医疗系统带来了沉重的负担。近年来,随着机器学习和数据分析技术的快速发展,我们得以运用这些先进工具对颅内感染进行更深入的研究,以期提高诊断的准确性和治疗的效率。
本研究采用了多种机器学习和数据分析技术,对大量医疗数据进行了挖掘和分析。首先,我们利用数据预处理技术,对原始数据进行了清洗、转换和标准化,确保数据的质量和一致性。接着,我们提取了与颅内感染相关的关键特征,如患者的年龄、性别、症状等,这些特征为后续的模型训练提供了基础。
在模型选择方面,我们尝试了多种分类算法,包括朴素贝叶斯、随机森林。通过对不同算法的比较和评估,我们发现随机森林模型在预测颅内感染方面表现出了较高的准确性。随机森林通过集成多棵决策树的预测结果,能够有效减少过拟合现象,提高模型的泛化能力。
为了进一步优化模型性能,我们采用了过采样技术来处理数据集中的类别不平衡问题。颅内感染作为少数类,其样本数量相对较少,这可能导致模型在训练过程中偏向于多数类。通过过采样技术,我们增加了少数类样本的数量,使得模型能够更好地学习少数类的特征,从而提高预测准确性。
在模型训练完成后,我们在验证集上进行了性能测试。通过计算准确率、精确率、召回率和F1值等指标,我们全面评估了模型的性能。结果显示,随机森林模型在颅内感染预测方面取得了令人满意的效果,能够为医生提供有力的诊断辅助工具。
除了模型预测外,我们还利用数据分析技术对颅内感染的相关因素进行了深入研究。通过对患者数据的统计分析,我们发现年龄、病史和某些特定症状与颅内感染的发生密切相关。这些发现为医生提供了更多的诊断线索和治疗依据。总的来说,本研究利用机器学习和数据分析技术对颅内感染进行了深入研究,取得了显著的成果。未来,我们将继续探索更多先进的算法和技术,以期在医疗领域发挥更大的作用,为患者提供更准确、更高效的诊断和治疗服务。
参考文献
[1] 周霜, 张瑞敏, 付立平. 个体化预测神经外科患者术后颅内感染风险的列线图模型的建立 [J]. 护士进修杂志, 2020, 35(20): 1843-7.
[2] 葛风, 蒋云召, 陆华, et al. 重型颅脑外伤术后颅内感染患者高迁移率族蛋白B-1和炎症因子表达水平 [J]. 中华医院感染学杂志, 2019, 29(17): 2661-4.
[3] 张翡, 赵建凯, 杨利辉, et al. 个体化预测重症高血压脑出血患者行有创颅内压监测术后发生颅内感染的风险预测Nomgram模型的建立 [J]. 四川医学, 2021, 42(10): 985-90.
[4] 张国新, 隋明亮, 张劲松. 降钙素原对开颅术后颅内感染的早期诊断及预后预测价值 [J]. 广东医学, 2015, 36(20): 3152-6.
[5] 黄胜明, 邢泽刚. 脑脊液与血清降钙素原检测对术后颅内感染的预测价值探讨 [J]. 当代医学, 2019, 25(28): 159-61.
[6] 聂柳, 崔勇, 刘兴吉, et al. 开颅手术患者术后炎症因子水平变化预测颅内感染的临床价值 [J]. 中国老年学杂志, 2017, 37(08): 1963-5.
[7] 宋超强, 赵保钢, 孙智宏. 探讨引发颅脑损伤术后并发颅内感染的高危因素及预后预测研究 [J]. 中国临床医生杂志, 2023, 51(04): 465-8.
[8] 张丹梅, 袁丽, 朱琪. 开颅手术后颅内感染风险预测模型构建及效果评价 [J]. 中国感染控制杂志, 2022, 21(05): 439-46.
[9] 张丹霓. 经颅多普勒在颅内感染和脑出血初期颅高压的对比 [J]. 中国实用医药, 2016, 11(10): 55-6.
[10] HONG Z, XIAOLU T, YANQIU L, et al. Amide Proton Transfer-Weighted (APTw) Imaging of Intracranial Infection in Children: Initial Experience and Comparison with Gadolinium-Enhanced T1-Weighted Imaging [J]. BioMed research international, 2020, 2020: 6418343.
[11] LAN G, XIAOLIANG Y, HUIKANG Y, et al. Application value analysis of magnetic resonance imaging and computed tomography in the diagnosis of intracranial infection after craniocerebral surgery [J]. World journal of clinical cases, 2020, 8(23): 5894-901.
[12] PENGFEI F, YI Z, JUN Z, et al. Prediction of Intracranial Infection in Patients under External Ventricular Drainage and Neurological Intensive Care: A Multicenter Retrospective Cohort Study [J]. Journal of Clinical Medicine, 2022, 11(14): 3973-.
[13] YEONG-JIN K, KYUNG-SUB M, KEE K S, et al. The difference in diffusion-weighted imaging with apparent diffusion coefficient between spontaneous and postoperative intracranial infection [J]. British journal of neurosurgery, 2014, 28(6): 765-70.